Mayug ManiparambilI recently completed my PhD at the SFI Centre for Research Training in Machine Learning (ML Labs), where I focused on multimodal learning, efficient vision-language model alignment, and low-data training strategies. My research explored representational similarity, "platonic representations" and universal embeddings in vision and language encoders, and was supervised by Prof. Noel O'Connor and the late Dr. Kevin McGuinness. Before this, I worked at Qure.ai as a computer vision researcher, developing weakly supervised and active learning-based models for cranial bleed detection and segmentation in CT imaging. During my undergrad I also collaborated with the Computational Imaging Lab at IIT Madras, under the guidance of Prof. Kaushik Mitra, on deep generative methods for phase retrieval and medical image denoising. I hold a dual degree (B.Tech + M.Tech) in Electrical Engineering with a specialization in Signal Processing from IIT Madras. My research has been published at CVPR, ICCV, and BMVC, and spans topics in Vision Language Models, LLMs, few-shot learning, and cross-modal pretraining. I recently interned at Amazon Robotics, Berlin, focusing on vision-language models and domain adaptation in robotic defect detection systems. Email / GitHub / Google Scholar / LinkedIn / CV / |

|
ResearchMy research interests include multimodal learning, representation alignment, computer vision, and developing efficient machine learning models with limited supervision. |

|
Harnessing Frozen Unimodal Encoders for Flexible Multimodal AlignmentMayug Maniparambil, Raiymbek Akshulakov, Yasser Abdelaziz Dahou Djilali, Sanath Narayan, Ankit Singh, Noel E. O'Connor CVPR (accepted), 2025 arxiv / code / We propose a novel framework for aligning vision and language modalities using frozen unimodal encoders. Our analysis reveals that semantically aligned encoder pairs can be effectively connected through lightweight projection layers. By training simple MLP projectors within this framework, we achieve 76% accuracy on ImageNet, while reducing data requirements by 20× and compute by 65× compared to traditional multimodal alignment approaches. This method significantly improves the accessibility of multimodal model development and enables flexible adaptation to tasks such as zero-shot segmentation, multilingual retrieval, and classification—by leveraging powerful, pretrained unimodal vision and language models. |

|
Pinpoint Counterfactuals: Reducing Social Bias in Foundation Models via Localized Counterfactual GenerationKirill Sirotkin, Marcos Escudero-Viñolo, Pablo Carballeira, Mayug Maniparambil, Catarina Barata, Noel E. O'Connor arXiv, 2024 arxiv / We introduce a localized counterfactual generation method that addresses societal biases in foundation models by constraining modifications to specific attribute-relevant regions through automated masking and guided inpainting. Applied to the Conceptual Captions dataset for creating gender counterfactuals, our approach achieves higher visual and semantic fidelity compared to existing methods, while preserving model performance on non-human-centric tasks. Fine-tuning models with our counterfactuals demonstrates measurable bias reduction across multiple metrics, establishing a framework for creating balanced datasets that enable both accurate bias profiling and effective mitigation. |
|
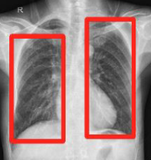
Test-Time Adaptation with SaLIP: A Cascade of SAM and CLIP for Zero-shot Medical Image SegmentationSidra Aleem, Fangyijie Wang, Mayug Maniparambil, Eric Arazo, Julia Dietlmeier, Kathleen Curran, Noel E. O'Connor, Suzanne Little CVPR Workshops (Oral), 2024 arxiv / code / We introduce SaLIP, a training-free framework that combines SAM and CLIP for zero-shot medical image segmentation. Our method uses CLIP to select relevant regions and SAM to segment them accurately, achieving significant improvements over baseline SAM across multiple medical imaging tasks. |
|
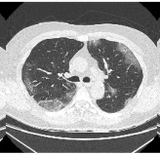
The STOIC2021 COVID-19 AI Challenge: Applying Reusable Training Pipelines to Medical ImagingDominik Müller, Mayug Maniparambil, et al. Medical Image Analysis, 2024 arxiv / This study presents the outcomes of the STOIC2021 challenge, highlighting the effectiveness of reusable training pipelines in medical imaging tasks related to COVID-19 diagnosis. |
|
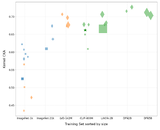
Do Vision and Language Encoders Represent the World Similarly?Mayug Maniparambil, Raiymbek Akshulakov, Yasser Abdelaziz Dahou Djilali, Sanath Narayan, Mohamed El Amine Seddik, Karttikeya Mangalam, Noel E. O'Connor CVPR, 2024 arxiv / code / This paper investigates whether independently trained vision and language encoders learn similar representations of the world. Utilizing Centered Kernel Alignment (CKA), the study finds that unaligned vision and language encoders exhibit semantic similarities in their representation spaces. The authors propose two methods—a Fast Quadratic Assignment Problem (QAP) optimization and a novel localized CKA metric-based matching—to align these representations without additional training. The effectiveness of these methods is demonstrated on downstream tasks such as cross-lingual and cross-domain caption matching and image classification. |
|
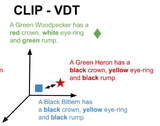
Enhancing CLIP with GPT-4: Harnessing Visual Descriptions as PromptsMayug Maniparambil, Chris Vorster, Derek Molloy, Noel Murphy, Kevin McGuinness, Noel E. O'Connor ICCV, 2023 arxiv / code / We demonstrate how GPT-4 can generate visually descriptive prompts to enhance CLIP’s zero-shot performance on fine-grained datasets. Our approach significantly improves accuracy and introduces a novel few-shot adapter that outperforms existing methods like CoCoOP. |

|
BaseTransformers: Attention over Base Data-Points for One Shot LearningMayug Maniparambil, Kevin McGuinness, Noel E. O'Connor BMVC, 2022 arxiv / We propose BaseTransformers, a novel approach that leverages attention mechanisms over base data-points to enhance one-shot learning performance. Our method achieves state-of-the-art results on multiple benchmarks. |
|
Phase Retrieval for Fourier Ptychography under Varying Amount of MeasurementsLokesh Boominathan, Mayug Maniparambil, Honey Gupta, Rahul Baburajan, Kaushik Mitra BMVC, 2018 arxiv / We explore phase retrieval techniques for Fourier Ptychography, focusing on scenarios with varying measurement quantities. Our findings contribute to improved imaging quality in computational photography. |
|
Design and source code from Jon Barron's website |